如需转载,标记出处
先建个快照
一。用mysqlimport导入CSV文件到数据库
1.创建一个你想要的数据库
create database uba;
分析导入文件的格式内容
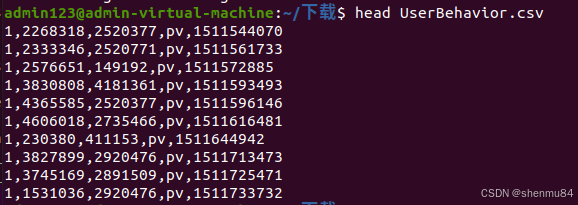
2.创建表(否则出现mysqlimport: Error: 1146, Table ’library.ab’ doesn’t exist, when using table: ab)
(你的csv文件名和表格名字一摸一样,大小写也是)
列的数据类型确认好,否则导入出错,(不然我也不用写下部分的 “二。删除数据库表”)
use uba;
create table userBehavior (
userID INT,
itemID INT,
categoryID INT,
behaviorType VARCHAR(5),
timestamps INT
);
3.重开终端,用下面的命令
如果数据1G以上,建议先放100条,万一出问题还可以改
普通终端:
head -n 101 userBehavior.csv > First100Rows.csv
mysql:
SET GLOBAL local_infile=1;
普通终端:
sudo systemctl restart mysql
mysqlimport --ignore-lines=1 --fields-terminated-by=, --local -u root -p uba First100Rows.csv
根据你自身情况去修改上面的命令,像我只需要改数据库名字和csv文件的名字就好
- mysqlimport: MySQL 的一个命令行工具,用来导入数据到 MySQL 表。
- –ignore-lines=1: 忽略 CSV 文件的第一行,通常用来跳过文件中的标题行。
- –fields-terminated-by=,: 指定字段分隔符,这里是逗号(,),表示 CSV 文件中的每一列数据是由逗号分隔的。
- –local: 表示数据文件在本地机器上,而不是数据库服务器上。没有这个参数的话,默认会从服务器上读取文件。
- -u root: 使用 root 用户连接 MySQL 数据库。
- -p: 提示输入密码,连接到 MySQL 时需要输入密码。
- Database: 目标数据库的名称,表示数据将被导入到这个数据库中。
- TableName.csv: 要导入的 CSV 文件的名称。
检查:(已经吃过一次删除一亿条数据的苦头,我这里用100条数据测试的)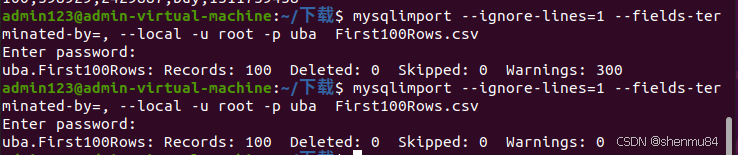 编辑如果和上图的第一个一样(warnings:300),进数据库用select查表数据,你的数据导入出错
编辑如果和上图的第一个一样(warnings:300),进数据库用select查表数据,你的数据导入出错
(以下是我出错的情况)
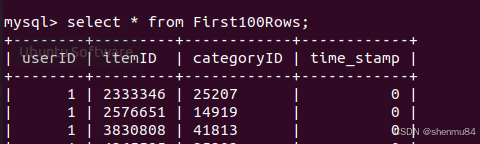
若和第二个一样即成功导入
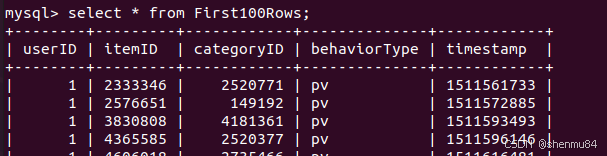
我最后用的是这个
mysqlimport –ignore-lines=1 –fields-terminated-by=, –local -u root -p uba userBehavior.csv
至此,你应该已经和现在的我一样等待这个数据的传递成功了,只不过数据太大需要等十几分钟

我搞定啦!
如果出现了下面的报错
(1)mysqlimport: Error: 3948, Loading local data is disabled; this must be enabled on both the client and server sides, when using table: UserBehavior
别担心,因为我也遇到了哈哈 :)
分析
mysql默认禁用 LOCAL 功能,用 LOAD DATA LOCAL 语句就会被禁止(我记得当时学sql注入的时候就有这个事例,别担心,咱用完再改回来就好)
解决办法
设置全局变量:
SET GLOBAL local_infile=1;
quit
如果出现这样的情况,ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘SET GLOBAL local_infile=1’ at line 1

去配置my.cnf文件里面加入
[mysqld]
local_infile=1
#重启
sudo systemctl restart mysql
(2)Undo Log error: No more space left over in system tablespace for allocating UNDO log pages
如果你数据一亿条以上,直接看下面的那个ERROR 3 (HY000)标题的,这个不行。
解决办法:
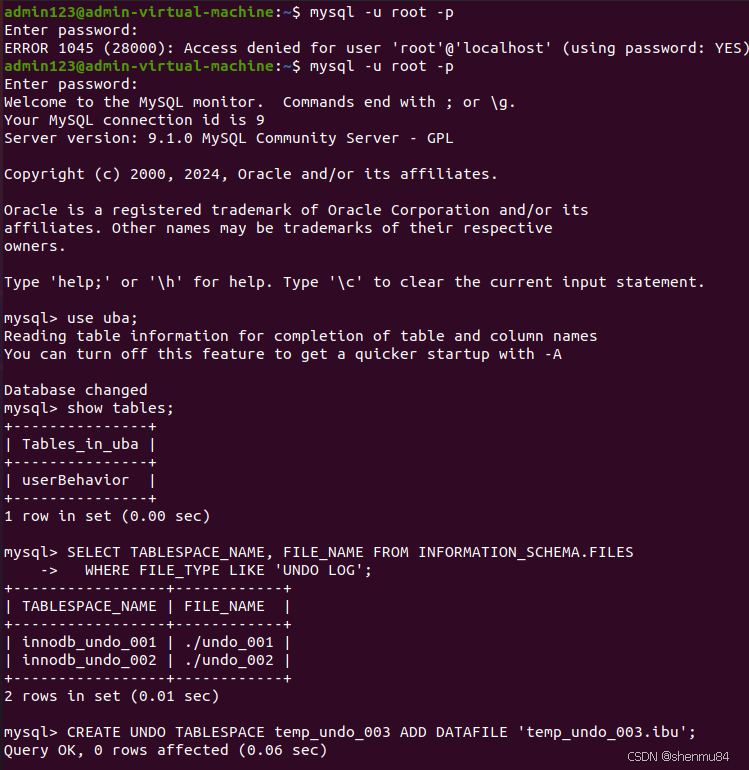

分析:
(我后来测试直接一键复制黏贴全部内容后出现bug,一条条复制黏贴没有任何问题)
--创建一个新的 undo 表空间:
CREATE UNDO TABLESPACE temp_undo_003 ADD DATAFILE 'temp_undo_003.ibu';
-- 创建 `temp_undo_003` 这个 undo 表空间,并为其添加数据文件。
-- 目的是临时提供 undo 作用,确保数据库在后续操作中始终有可用的 undo 表空间。
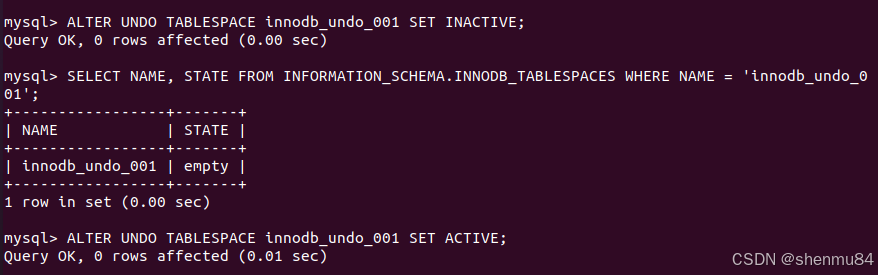
--设置 `innodb_undo_001` 为 INACTIVE(非活动状态):
ALTER UNDO TABLESPACE innodb_undo_001 SET INACTIVE;
-- 让 `innodb_undo_001` 进入 `INACTIVE` 状态,意味着它不再接受新的 undo 事务。
-- 等待 `innodb_undo_001` 变成 `empty` 状态:
SELECT NAME, STATE FROM INFORMATION_SCHEMA.INNODB_TABLESPACES WHERE NAME = 'innodb_undo_001';
--监测表空间状态,确保 undo 数据已经清空(`STATE = 'empty'`)。
--重新激活 `innodb_undo_001`:
ALTER UNDO TABLESPACE innodb_undo_001 SET ACTIVE;
-- 使 `innodb_undo_001` 重新可用,但此时它已经完成了手动截断。
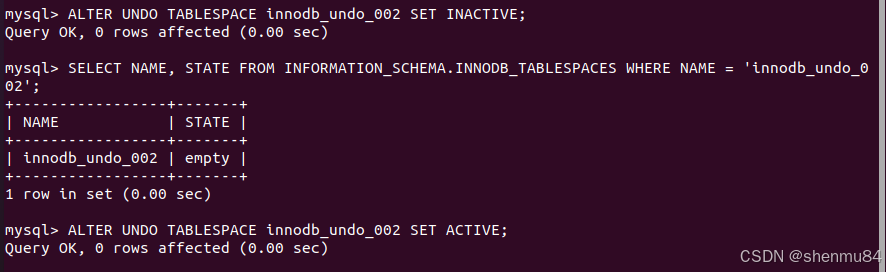
-- 对 `innodb_undo_002` 重复上述步骤:
--先设置 `INACTIVE`,等待变为空,再设置 `ACTIVE`,完成手动截断。
ALTER UNDO TABLESPACE innodb_undo_002 SET INACTIVE;
SELECT NAME, STATE FROM INFORMATION_SCHEMA.INNODB_TABLESPACES WHERE NAME = 'innodb_undo_002';
ALTER UNDO TABLESPACE innodb_undo_002 SET ACTIVE;
--当 `innodb_undo_001` 和 `innodb_undo_002` 都被清理后:
--关闭并删除 `temp_undo_003`:
ALTER UNDO TABLESPACE temp_undo_003 SET INACTIVE;
DROP UNDO TABLESPACE temp_undo_003;
MySQL 提供“UNDO 日志文件”来回滚更改的方法。我存了一亿的数据,日志表空间因为事务积累导致文件增大,把它清空就行。
需要至少 2 个活动 undo 表空间,用 temp_undo_003 作为过渡,确保整个过程中始终有可用的 undo 表空间
总结
这个过程是,手动 undo 表空间截断和优化的操作,利用 临时 undo 表空间(temp_undo_003) 来保持数据库稳定性,最终完成 innodb_undo_001 和 innodb_undo_002 的清理,并释放存储空间。
参考文档:
https://dev.mysql.com/doc/refman/8.0/en/innodb-undo-tablespaces.html
(3)列的值为0
如果列没有设置数据,则默认值有
我这边的情况是有五列值,创建表时只设置了四个
二。删除数据库中有一亿数据的表
最简单的方法:
删除该表中的所有行,用截断表
TRUNCATE TABLE LargeTable
GO
看到这行命令成功的删除了数据,顿时觉得自己一下午的努力都白费
另分一篇帖子给用pt-archiver的人解决BUG吧